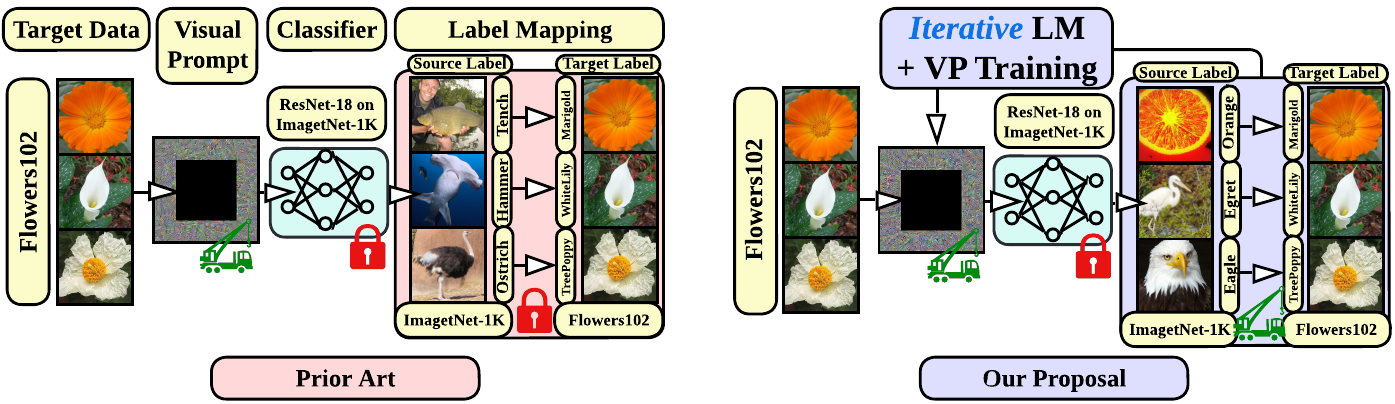
Existing label mapping methods seem ruleless? We intertwine the VP dynamic and the label mapping to boost the performance and interpretability of VP.
Abstract
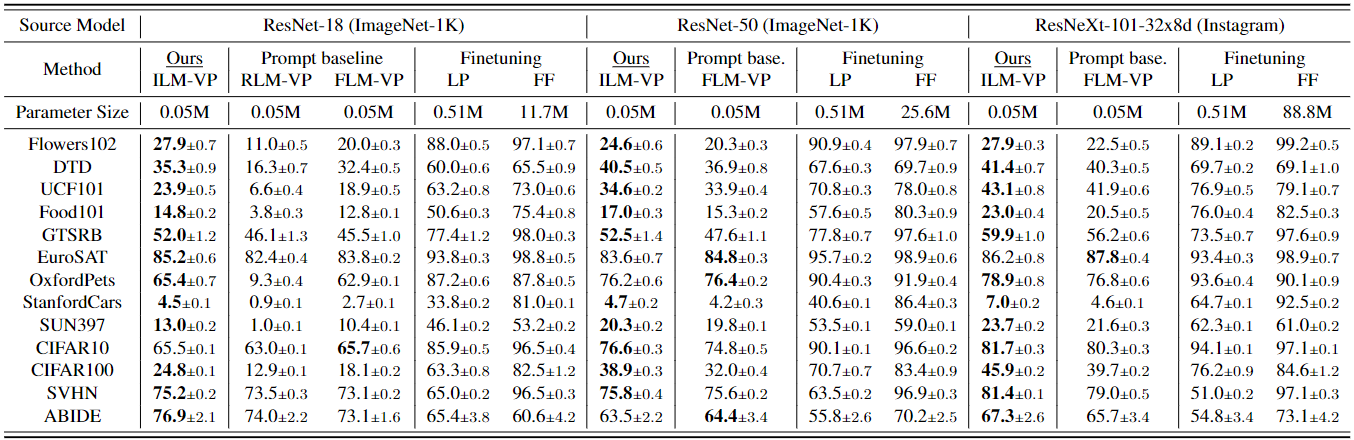
We revisit and advance visual prompting (VP), an input prompting technique for vision tasks. VP can reprogram a fixed, pre-trained source model to accomplish downstream tasks in the target domain by simply incorporating universal prompts (in terms of input perturbation patterns) into downstream data points. Yet, it remains elusive why VP stays effective even given a ruleless label mapping (LM) between the source classes and the target classes. Inspired by the above, we ask: How is LM interrelated with VP? And how to exploit such a relationship to improve its accuracy on target tasks? We peer into the influence of LM on VP and provide an affirmative answer that a better ‘quality’ of LM (assessed by mapping precision and explanation) can consistently improve the effectiveness of VP. This is in contrast to the prior art where the factor of LM was missing. To optimize LM, we propose a new VP framework, termed ILM-VP (iterative label mapping-based visual prompting), which automatically re-maps the source labels to the target labels and progressively improves the target task accuracy of VP. Further, when using a contrastive language-image pretrained (CLIP) model, we propose to integrate an LM process to assist the text prompt selection of CLIP and to improve the target task accuracy. Extensive experiments demonstrate that our proposal significantly outperforms state-of-the-art VP methods. As highlighted below, we show that when reprogramming an ImageNet-pretrained ResNet-18 to 13 target tasks, our method outperforms baselines by a substantial margin, e.g., 7.9% and 6.7% accuracy improvements in transfer learning to the target Flowers102 and CIFAR100 datasets. Besides, our proposal on CLIP-based VP provides 13.7% and 7.1% accuracy improvements on Flowers102 and DTD respectively.
Why Label Mapping Matters?
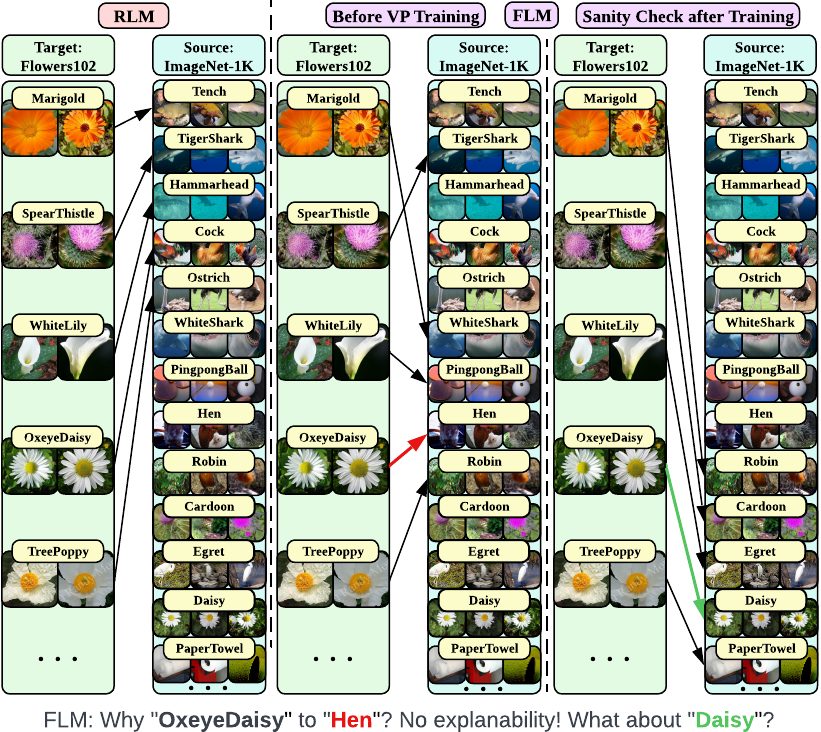
VP is an emerging technique for transfer learning which needs an input perturbation pattern and a label mapping strategy. However, although the SOTA label mapping method (frequency label mapping, FLM) improves performance over the random label mapping (RLM) method, it fails to deliver clear interpretability. It is worth noting that the updating of VP pattern induces prediction dynamics, which leads to the inconsistency between pre- and post-prompt prediction frequency.
Our Proposal: ILM-VP
We propose to take the LM dynamics into the prompt learning process. Namely, we alternatively optimize the VP pattern and the LM strategy.

Performance Boost
Our method yields substantial accuracy improvement on multiple datasets.
Interpretability Merit
Our method unveils source-target label pairs that share similar features in the vision domain.
% ## Video
% —
Acknowledgement
The work of A. Chen, Y. Yao, Y. Zhang, and S. Liu was supported by the DARPA RED program and National Science Foundation (NSF) Grant IIS-2207052.
Citation
@article{chen2022understanding,
title={Understanding and Improving Visual Prompting: A Label-Mapping Perspective},
author={Chen, Aochuan and Yao, Yuguang and Chen, Pin-Yu and Zhang, Yihua and Liu, Sijia},
journal={arXiv preprint arXiv:2211.11635},
year={2022}
}