Group projects highlights
Authors marked in blue indicate our group members, and “*” indicates equal contribution.
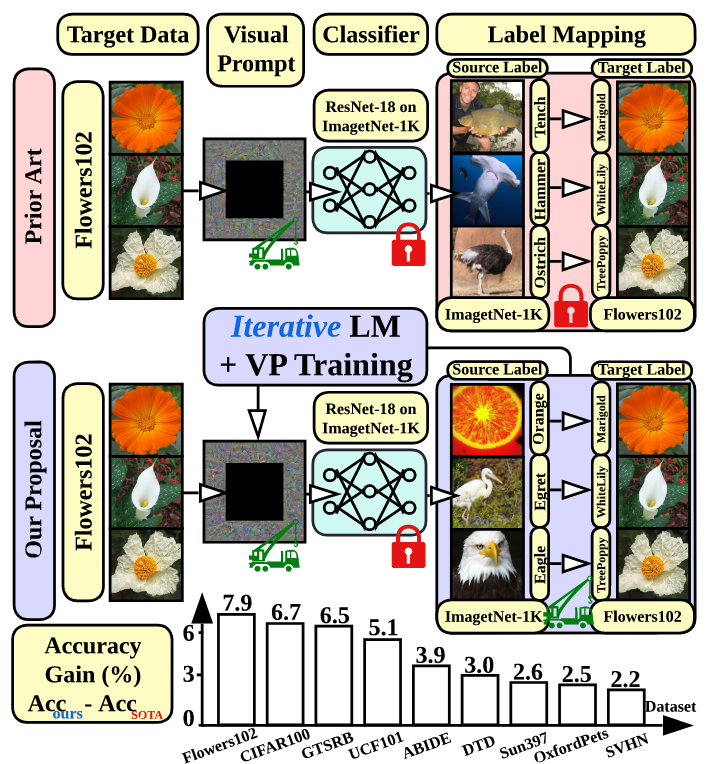
We revisit and advance visual prompting (VP), an input prompting technique for vision tasks. VP can reprogram a fixed, pre-trained source model to accomplish downstream tasks in the target domain by simply incorporating universal prompts (in terms of input perturbation patterns) into downstream data points. Yet, it remains elusive why VP stays effective even given a ruleless label mapping (LM) between the source classes and the target classes. Inspired by the above, we ask: How is LM interrelated with VP? And how to exploit such a relationship to improve its accuracy on target tasks? We peer into the influence of LM on VP and provide an affirmative answer that a better ’quality’ of LM (assessed by mapping precision and explanation) can consistently improve the effectiveness of VP. This is in contrast to the prior art where the factor of LM was missing. To optimize LM, we propose a new VP framework, termed ILM-VP (iterative label mapping-based visual prompting), which automatically re-maps the source labels to the target labels and progressively improves the target task accuracy of VP. Further, when using a contrastive language-image pretrained (CLIP) model, we propose to integrate an LM process to assist the text prompt selection of CLIP and to improve the target task accuracy. Extensive experiments demonstrate that our proposal significantly outperforms state-of-the-art VP methods. As highlighted below, we show that when reprogramming an ImageNet-pretrained ResNet-18 to 13 target tasks, our method outperforms baselines by a substantial margin, e.g., 7.9% and 6.7% accuracy improvements in transfer learning to the target Flowers102 and CIFAR100 datasets. Besides, our proposal on CLIP-based VP provides 13.7% and 7.1% accuracy improvements on Flowers102 and DTD respectively.
A. Chen, Y. Yao, P. Chen, Y. Zhang, S. Liu
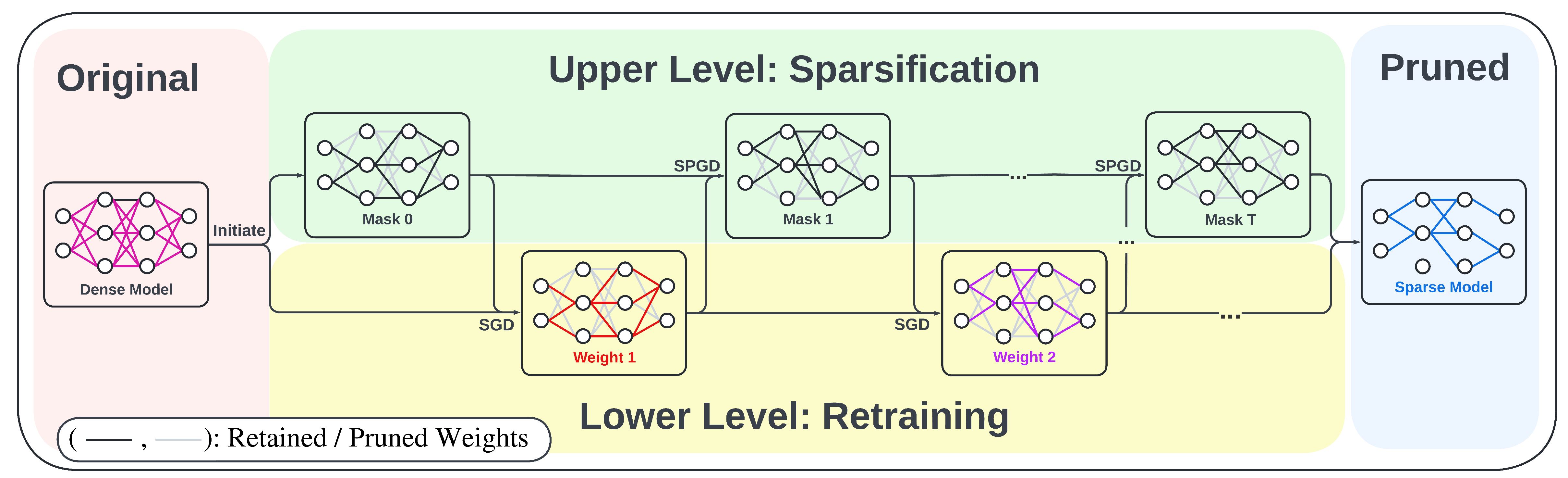
In this work, we advance the optimization foundations of the pruning problem and close the gap between pruning accuracy and pruning efficiency. we formulate the pruning problem from a fresh and novel viewpoint, bi-level optimization (BLO). We show that the BLO interpretation provides a technically-grounded optimization base for an efficient implementation of the pruning-retraining learning paradigm used in IMP. We also show that the proposed bi-level optimization-oriented pruning method (termed BIP) is a special class of BLO problems with a bi-linear problem structure. Through thorough experiments on various datasets and model architectures, we demonstrate that BiP can achieve the state-of-the-art pruning accuray in both structured and unstructured pruning setting. and is computationally as efficient as the one-shot pruning schemes, demonstrating an 2~7 times speed up over the current SOTA pruning baseline (IMP) for the same level of model accuracy and sparsity.
Y. Zhang*, Y. Yao*, P. Ram, P. Zhao, T. Chen, M. Hong, Y. Wang, S. Liu
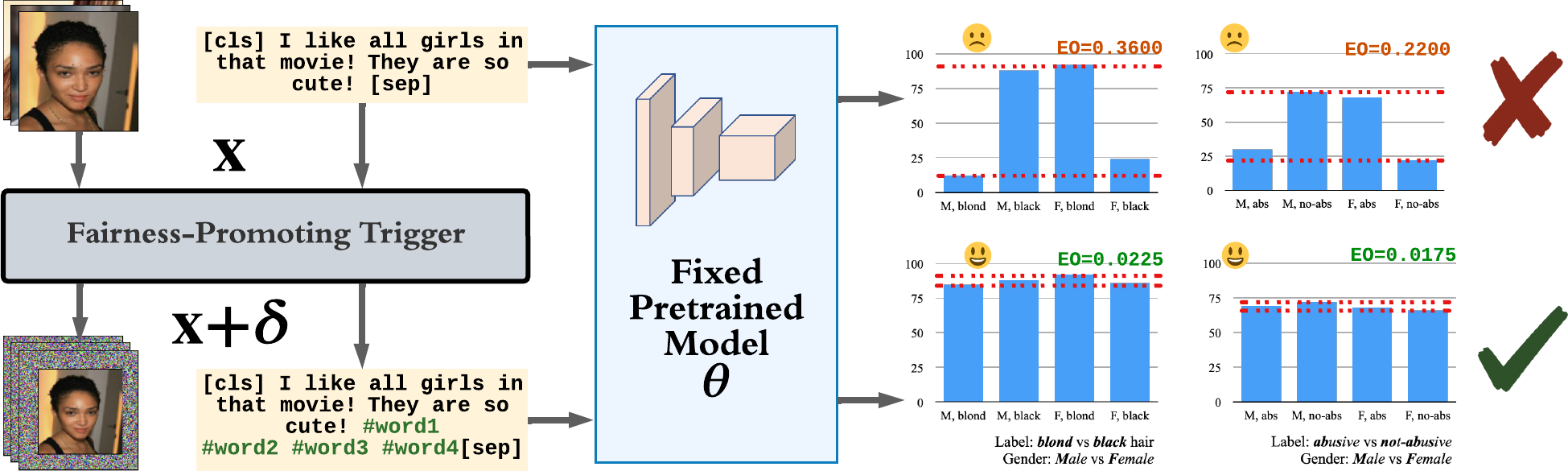
Despite a surge of recent advances in promoting machine Learning (ML) fairness, the existing mainstream approaches mostly require retraining or finetuning the entire weights of the neural network to meet the fairness criteria. However, this is often infeasible in practice for those large-scale trained models due to large computational and storage costs, low data efficiency, and model privacy issues. In this paper, we propose a new generic fairness learning paradigm, called FairnessReprogram, which incorporates the model reprogramming technique. Specifically, FairnessReprogram considers the case where models can not be changed and appends to the input a set of perturbations, called the fairness trigger, which is tuned towards the fairness criteria under a min-max formulation. We further introduce an information-theoretic framework that explains why and under what conditions fairness goals can be achieved using the fairness trigger. Extensive experiments on both NLP and CV datasets demonstrate that our method can achieve better fairness improvements than retraining-based methods with far less data dependency under two widely-used fairness criteria.
G. Zhang*, Y. Zhang*, Y. Zhang, W. Fan, Q. Li, S. Liu, S. Chang
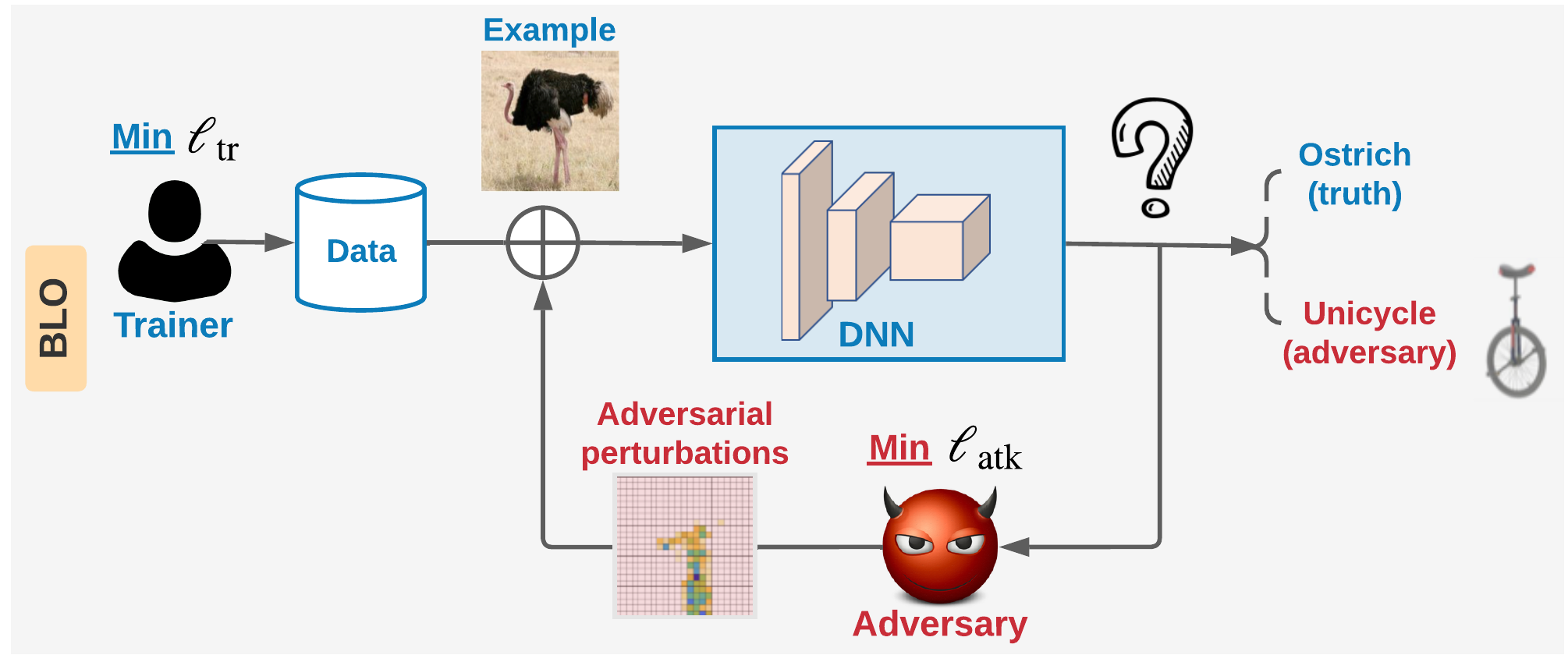
This work reformulates the problem of adversarial training (AT) to a bi-level optimization problem (BLO). BLO advances the optimization foundations of AT. We first show that the commonly-used Fast-AT is equivalent to using a stochastic gradient algorithm to solve a linearized BLO problem involving a sign operation. However, the discrete nature of the sign operation makes it difficult to understand the algorithm performance. Inspired by BLO, we design and analyze a new set of robust training algorithms termed Fast Bi-level AT (Fast-BAT), which effectively defends sign-based projected gradient descent (PGD) attacks without using any gradient sign method or explicit robust regularization. In practice, we show that our method yields substantial robustness improvements over multiple baselines across multiple models and datasets.
Y. Zhang*, G. Zhang*, P. Khanduri, M. Hong, S. Chang, and S. Liu
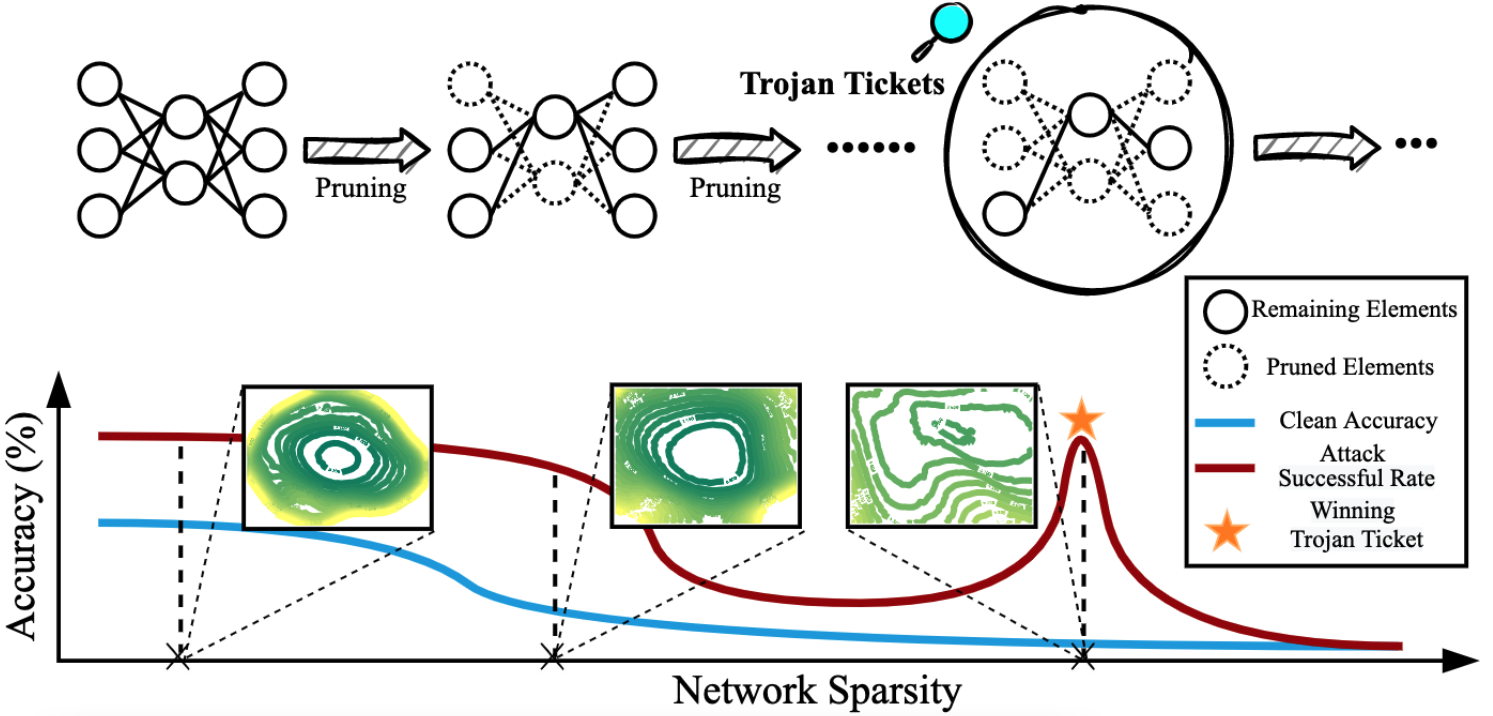
This paper revealed that for a backdoored model, Trojan features learned are more stable against pruning than benign features! We further observed the existence of the ‘winning Trojan ticket’ which preserves the Trojan attack performance while retaining chance-level performance on clean inputs. Further, we propose a clean data-free algorithm to detect and reverse engineer the Trojan attacks.
T. Chen*, Z. Zhang*, Y. Zhang*, S. Chang, S. Liu, Z. Wang
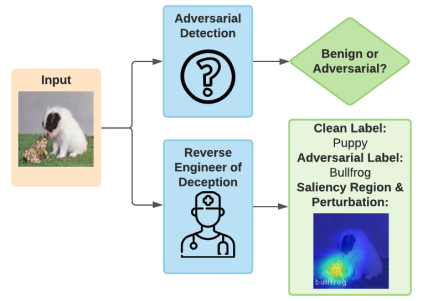
In this paper, we study the problem of Reverse Engineering of Deceptions (RED), with the goal to recover the attack toolchain signatures (e.g. adversarial perturbations and adversary salience image regions) from an adversarial instance. Our work makes a solid step towards formalizing the RED problem and developing a systematic RED pipeline, covering not only a solution method but also a complete set of evaluation metrics.
Y. Gong*, Y. Yao*, Y. Li, Y. Zhang, X. Liu, X. Lin, S. Liu
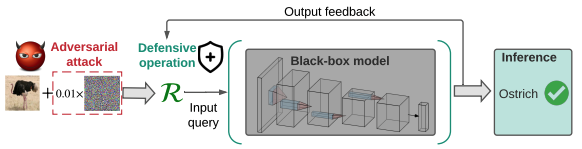
In this paper, we study the problem of black-box defense, aiming to secure black-box models against adversarial attacks using only input-output model queries. We integrate denoised smoothing (DS) with ZO (zerothorder) optimization to build a feasible black-box defense framework. We further propose ZO-AE-DS, which leverages autoencoder (AE) to bridge the gap between FO and ZO optimization.
Y. Zhang, Y. Yao, J. Jia, J. Yi, M. Hong, S. Chang, S. Liu
ICLR’22 (spotlight, acceptance rate 5%)